产品说明书
面向企业客户的正式产品资料,系统说明核心能力、典型场景、安全边界与交付方式。
Sage(明略)· 打造企业级 AI 运维专家团队
让每个工程师,都有 AI 运维专家支撑
7 支领域专家全天候在线,故障止于发现,风险消于预警
你的团队现在面对的是什么
每一个在规模化阶段的技术团队,都在和同一批问题缠斗:
- 用户反馈"页面打不开""提交一直转圈",工程师盯着十几个控制台,凭经验和运气在日志堆里找答案
- 告警触发,是 502?504?还是数据库慢?每次排查都要重走一遍相同的流程,没有任何复用
- 每天早上例行巡检,手动执行十几条命令、登录三四个平台,这些重复劳动占掉 SRE 30% 以上的工时
- 告警风暴期间一小时几百条,工程师根本无暇研判,疲于奔命却始终被动
这不是人的问题,是规模到了之后,人工运维模式本身遇到了上限。
Sage(明略) 帮助企业基础设施团队打造自己的 AI 运维专家团队。它以自然语言为入口,接入你已有的可观测性体系,用 7 支领域 AI 运维专家协同作战,让故障诊断从小时级压缩到分钟级,让例行运维从人工执行变成自动完成。
不替换你的工程师,而是让每个工程师背后都有一支 AI 运维专家团队。
产品界面概览
主对话界面
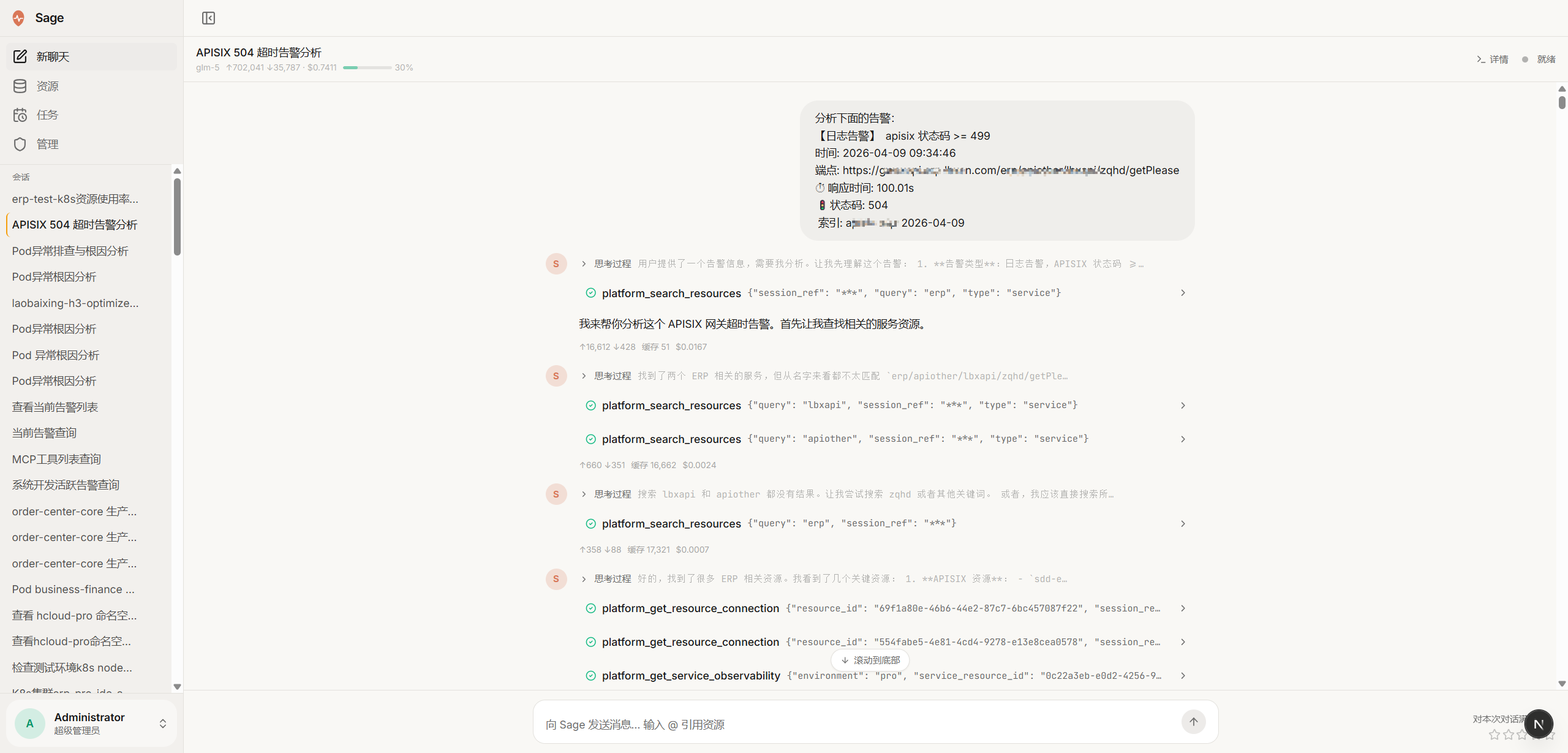
多代理执行过程透明化
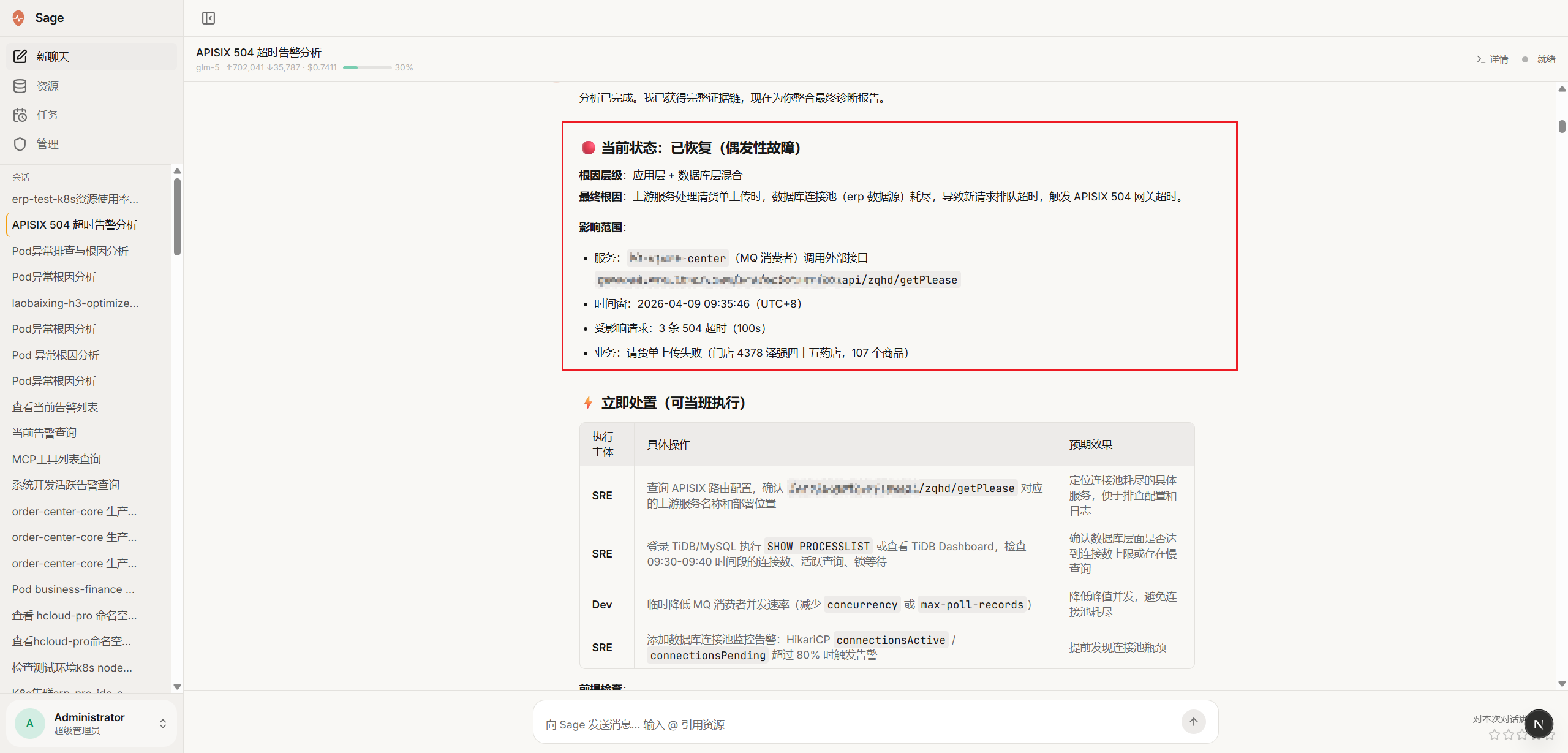
自动化巡检 & 结构化报告
资源管理 & 权限体系
核心能力
一、多系统关联诊断,MTTR 从小时到分钟
SRE 排障慢,根本原因不是工程师不够快,而是信息分散在太多系统里,人工串联太费时间。
明略将你已有的可观测性数据统一整合,AI 跨系统并行分析,输出带根因定位的诊断报告。同一个问题,过去需要 3 个人协作 40 分钟,现在 1 个人 3 分钟拿到同等质量的分析结论。
二、接入你已有的可观测性体系,而非替换它
明略不是一套新的监控体系,而是在你现有工具链之上增加 AI 推理层。无论你的团队用的是哪一套工具组合,明略都可以接入并联合分析:
| 可观测性维度 | 接入能力 | 当前已支持(举例) |
|---|---|---|
| 指标监控 | PromQL 查询、阈值分析、趋势对比 | Prometheus、VictoriaMetrics 等 |
| 链路追踪 | Trace 查询、慢 Span 定位、依赖拓扑分析 | SkyWalking、Jaeger、Zipkin 等 |
| 日志检索 | 全文检索、聚合统计、错误模式提取 | Elasticsearch、Loki、ClickHouse 等 |
| API 网关 | 访问日志分析、错误率统计、限流状态 | APISIX、Nginx、Kong、Traefik 等 |
| 关系型数据库 | 慢查询、锁分析、复制延迟、容量趋势 | MySQL、TiDB、PostgreSQL 等 |
| 缓存 / 消息 | 命中率、内存水位、消费延迟 | Redis、Kafka 等 |
| 容器编排 | Pod 状态、资源水位、事件日志 | Kubernetes 等 |
以上为当前已实现能力的代表性举例,并非排他列表。明略的扩展架构支持持续接入新的数据源和工具类型。
三支柱数据(Metrics / Traces / Logs)在同一个对话里关联分析,不再需要工程师在多个系统间手动拼图。
三、AI 运维专家团队,复杂问题精准路由
单一 AI 面对数据库、容器平台、服务链路、搜索集群等多个领域时,上下文混杂、技能误选是必然结果。明略采用 "AI 调度中枢 + 领域运维专家" 的多代理架构,构成一支真正可用的 AI 运维专家团队:
用户(自然语言描述) / 计划任务(Cron 触发)
↓
AI 调度中枢(ORCHESTRATOR)
问题定界 → 领域判断 → 路由 → 结论汇聚
↓
┌──────┬──────┬──────┬──────┬──────┬──────┬──────┐
数据库 数据库 数据库 容器 服务 搜索 安全 ··· 自定义
运行时 同步链路 巡检 集群 排障 集群 守卫 运维专家 +
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
各领域专属 Skills(白名单隔离,互不干扰,能力边界 = 工具边界)
| AI 运维专家 | 专项能力 |
|---|---|
| AI 调度中枢 | 唯一对外入口;问题定界、路由调度、多专家协调、结论汇总 |
| 数据库运行时专家 | 慢查询、锁等待、热点、连接池(MySQL / TiDB 等) |
| 数据库同步链路专家 | 主从复制、CDC 链路、binlog 延迟排查 |
| 数据库巡检专家 | 健康快照、容量趋势、集群状态评估 |
| 容器集群专家 | Pod 异常、Node 压力、资源配额、集群巡检(Kubernetes 等) |
| 服务排障专家 | 接口错误、链路追踪分析、日志关联、网关日志(各类链路追踪 / 网关工具) |
| 搜索集群专家 | 索引健康、分片分配、JVM、慢查询(Elasticsearch 等) |
| 安全守卫 | 越权操作识别、危险命令拦截、敏感读取阻断 |
| 自定义运维专家 | 资源纳管、预算规划、成本分析、权限管控——可按业务需求持续扩展 |
每个运维专家只加载本领域 Skills,误选概率接近零;AI 调度中枢负责协调,不下钻具体分析,职责分离、结构稳定。专家数量和能力边界随工具扩展,没有上限。
四、自动化巡检引擎,把 SOP 变成定时任务
明略的计划任务引擎将团队积累的巡检 SOP 转化为可调度的 AI 自主执行任务:
- 非交互执行模式:AI 自主完成,遇到不确定情况写入阻塞项继续执行,不等待人工干预
- 结构化巡检报告:输出标准报告(整体结论 / 逐项检查结果 / 阻塞项 / 处置建议),前端可回放完整执行过程
- 精准通知策略:区分"执行异常"与"巡检结论"两个维度,只在异常时推送,避免告警疲劳
- 三种调度模式:周期 Cron / 一次性定时 / 手工触发,覆盖所有运营场景
五、执行过程完全透明,诊断结论可追溯
AI 不是黑盒。明略在主对话中实时展示每个专家代理的执行轨迹:
- 哪个专家被调用、调用了哪些工具、每步推理依据是什么
- 执行历史完整保留,刷新页面后仍可逐步回放
- 所有命令执行、资源访问、AI 输出均有完整审计记录
工程师可以学习 AI 的排查路径;管理者可以审计 AI 的每一次操作;合规团队可以查阅完整访问日志。
六、凭据安全,通过架构设计保障而非依赖规范
明略采用 凭据零暴露架构,从根本上消除凭据通过 AI 泄露的风险:
- AI 只获得资源的"引用标识",密码和密钥存于加密隔离区(AES-256-GCM),全程不经过 AI 推理路径
- 平台输出层对所有 AI 响应做流式脱敏兜底,Token、密钥、私钥等敏感内容自动过滤
- DDL 变更、数据删除等危险操作默认拦截,需用户明确授权后方可执行
典型应用场景
场景一:用户反馈"页面打不开 / 一直转圈"
最难排查的往往不是告警,而是用户主动反馈的模糊症状——工程师不知道从哪里开始查。
客服转来:多个用户反馈商品详情页加载很慢,部分白屏
工程师对明略:商品详情页用户反馈慢,帮我查一下
明略自动执行:
① 网关访问日志(近 30 分钟):/api/product/{id} P99 延迟 12s,错误率 3.2%
② 链路追踪:慢请求 Trace → product-service → inventory-service 调用超时
③ inventory-service 日志:连接池耗尽,等待队列积压 340 个请求
④ 数据库:inventory_db 出现大量慢查询,stock_check 接口触发全表扫描
⑤ 指标监控:inventory-service 实例数 2 个,CPU 98%,明显资源不足
根因:inventory_db 慢查询导致 inventory-service 连接池耗尽,
反压传导至 product-service,最终用户侧感知为页面加载慢
建议:临时扩容 inventory-service 实例;优化慢查询 SQL(附索引建议)
场景二:502 Bad Gateway 快速定位
监控告警:order-service 502 错误率突增至 8%
工程师对明略:order-service 刚开始报 502,帮我查
明略自动执行:
① 网关错误日志:502 集中在 /api/order/create,上游连接被拒绝
② 容器平台:order-service 6 个 Pod 中有 4 个处于 Terminating 状态
③ 容器事件日志:OOMKilled × 4,内存限制 512Mi,实际使用峰值 891Mi
④ 应用日志(最近 1 小时):大量 Java heap space 异常,从 14:22 开始
根因:order-service 存在内存泄漏,促销期间流量上升触发 OOM,
Pod 被反复 Kill,网关上游健康实例不足导致 502
建议:立即调高内存 Limit 至 1.5Gi 缓解;排查 14:22 前后的代码变更
场景三:504 Gateway Timeout 根因分析
用户投诉:结算页面提交订单一直超时
工程师对明略:结算接口 504,帮我定位根因
明略自动执行:
① 网关日志:/api/checkout 响应时间持续 > 30s,触发网关超时阈值
② 链路追踪:checkout-service → payment-service → 第三方支付回调等待
③ payment-service 日志:第三方支付 SDK 连接超时,重试 3 次,累计耗时 28s
④ 网络指标:payment-service 出口带宽正常,DNS 解析耗时异常(avg 4.2s)
根因:DNS 解析异常导致第三方支付 SDK 连接耗时翻倍,
叠加重试机制,总耗时超过网关 30s 超时阈值
建议:检查 payment-service 所在 Node 的 DNS 配置;
短期可在 payment-service 中配置支付域名 hosts 绕过 DNS 解析
场景四:P0 故障快速止血(变更引入)
00:17 监控告警:支付成功率从 99.8% 跌至 91%
工程师对明略:支付成功率刚开始下跌,帮我查
明略(2 分 40 秒后):
根因:payment_records 表 DDL 变更(00:09 上线)新增字段未设 DEFAULT 值,
导致所有 INSERT 语句失败,应用报 Data too long for column
影响范围:payment-service 全部实例,00:09 起
建议:回滚该字段变更(附回滚 SQL),或补加 DEFAULT 值后重启服务
00:21 工程师执行回滚,成功率恢复 99.9%
全程 4 分钟,MTTR 较历史均值降低 87%
场景五:容量风险提前预警(自动化巡检)
Cron: 每天 07:30 — 核心数据库集群容量巡检
明略输出:
⚠️ order_db 磁盘使用率 87%,7 日增速 1.2%/天,预计 11 天触及扩容阈值
⚠️ user_db 缓冲池命中率 89.3%,建议内存扩容至 64GB(当前 32GB)
✓ inventory_db 各项指标健康
✓ 主从同步延迟均 < 500ms
结果:DBA 在故障发生前 11 天收到预警,从容完成扩容
不再依赖"磁盘满了才知道"的被动响应模式
场景六:大促前全链路性能基线
工程师:大促前帮我跑一遍 order 链路的性能基线
明略(覆盖网关 → 服务 → 数据库 → 缓存完整链路):
网关层:/api/order/* P50 45ms / P99 320ms(历史大促水位 P99 < 500ms ✓)
数据库:慢查询日均 8 条,2 条 > 1s(⚠️ 建议大促前优化)
容器:order-service CPU 峰值 78%,自动扩容阈值 80%(⚠️ 弹性空间偏小)
缓存:命中率 96.2%(✓)
建议:优先处理 2 条慢 SQL;HPA 阈值调整至 70%,留出更多弹性余量
企业价值
一支 AI 运维专家团队,带来可量化的回报
| 指标 | 传统模式 | 配备 AI 运维专家团队后 |
|---|---|---|
| 故障根因定位(MTTR) | 40 分钟(多人协作) | < 5 分钟(AI 运维专家辅助) |
| 例行巡检耗时 | 每人每天 2–3 小时 | 全自动,人工零介入 |
| 跨系统排查切换 | 人工在 5–10 个控制台间切换 | 单一对话,AI 专家自动联动 |
| On-call 疲劳 | 人工逐条研判告警 | AI 运维专家直出根因结论 |
| 新人上手速度 | 依赖老员工传帮带 | AI 运维专家引导完成标准排查流程 |
| 团队能力天花板 | 受限于人员编制与经验积累 | 能力边界 = 工具边界,随 Skills 扩展无上限 |
小团队,扛住大规模
规模化不应该靠堆人。AI 运维专家团队 7×24 在线,不疲倦、不请假、不断档。5 人团队通过明略,可以稳定支撑过去需要 15 人才能覆盖的基础设施规模。
从被动救火到主动防御
传统模式:系统出问题 → 告警响 → 人去处理。明略把这条链路前移:
- 例行巡检自动化:容量预警、性能退化、配置漂移在演变为故障之前就被发现
- 结构化报告留存:每次巡检结论可查可比,趋势变化一目了然
- 变更后自动核查:发布后 AI 运维专家自动检查服务健康状态,第一时间发现变更引入的异常
经验沉淀,告别能力断层
运维知识不再依附于特定工程师。AI 运维专家把团队最佳实践固化为可复用的 Skills,新人第一天就能用专家级排查流程解决问题。核心成员离职不会带走经验,传承在系统里,不在个人身上。
工程师专注高价值工作
重复性劳动(例行巡检、标准化排查、数据收集)由 AI 运维专家承担;需要判断力的工作(架构优化、容量规划、变更决策)由工程师主导。SRE 的工程价值得到放大,而不是被淹没在 on-call 和重复操作里。
安全合规,满足企业级要求
- 凭据零暴露架构:通过设计保障,而非依赖规范约束
- 细粒度三级权限模型:组织隔离、资源授权、跨组共享均可管控
- 完整审计链路:AI 的每一次操作都可查可溯
- AI 危险操作默认拦截:DDL、数据删除需显式授权,杜绝误操作生产数据
技术架构
Agent Runtime:原生工具直连,能力无损耗
明略的 Agent Runtime 直接调用各类原生命令行工具(mysql、kubectl、redis-cli、curl 等),而非通过自定义中间层封装:
- 能力边界 = 工具本身的全量能力,无任何功能裁剪
- AI 可自由组合命令(管道 / 重定向 /
grep/awk/jq)应对任意场景 - 工具生态完整可用,如数据库诊断工具(
pt-query-digest等)AI 均可直接调用
资源按需发现,支持任意规模
资源列表不预注入 AI 上下文,由 AI 按需动态查询、按权限过滤:
- 纳管数千个数据库实例也不会导致上下文膨胀
- 新增资源实时可用,无需重启任何服务
- 每次查询严格权限过滤,AI 只能访问当前用户已授权的资源
多代理技能白名单隔离
每个领域专家的可用技能通过白名单精确控制,新技能上线只影响指定专家,不会意外扩散到其他代理,保证系统行为稳定可预期。
部署方式
明略支持完全私有化部署,数据不出企业内网。提供 Docker Compose 和 Kubernetes Helm Chart 两种交付方式,开箱即用。
环境要求
| 组件 | 最低配置 | 推荐配置 |
|---|---|---|
| Agent 运行服务器 | 4 核 8 GB | 8 核 16 GB |
| 元数据数据库 | MySQL 8.0+ | MySQL 8.0+(独立实例) |
| 网络 | 可访问 LLM API | 内网 + LLM 专线或代理 |
支持的大模型
- Claude(Anthropic) — 推荐,综合效果最佳
- 支持 OpenAI 兼容接口
路线图
- 更多数据源接入 — Redis 深度诊断、消息队列(Kafka / RocketMQ)延迟分析
- 告警直接触发分析 — 接收告警 Webhook,自动触发 AI 根因分析,无需人工介入
- 变更风险预评估 — 发布前分析变更影响面,提前识别高风险变更
- 全自动 RCA 报告 — 故障复盘报告一键生成,含根因、影响范围、完整时间线
- 多 LLM 支持 — 接入私有化部署的开源大模型
Sage(明略)—— 打造企业级 AI 运维专家团队,让每个工程师都有专家支撑