产品截图
每一个交互都经过深度打磨
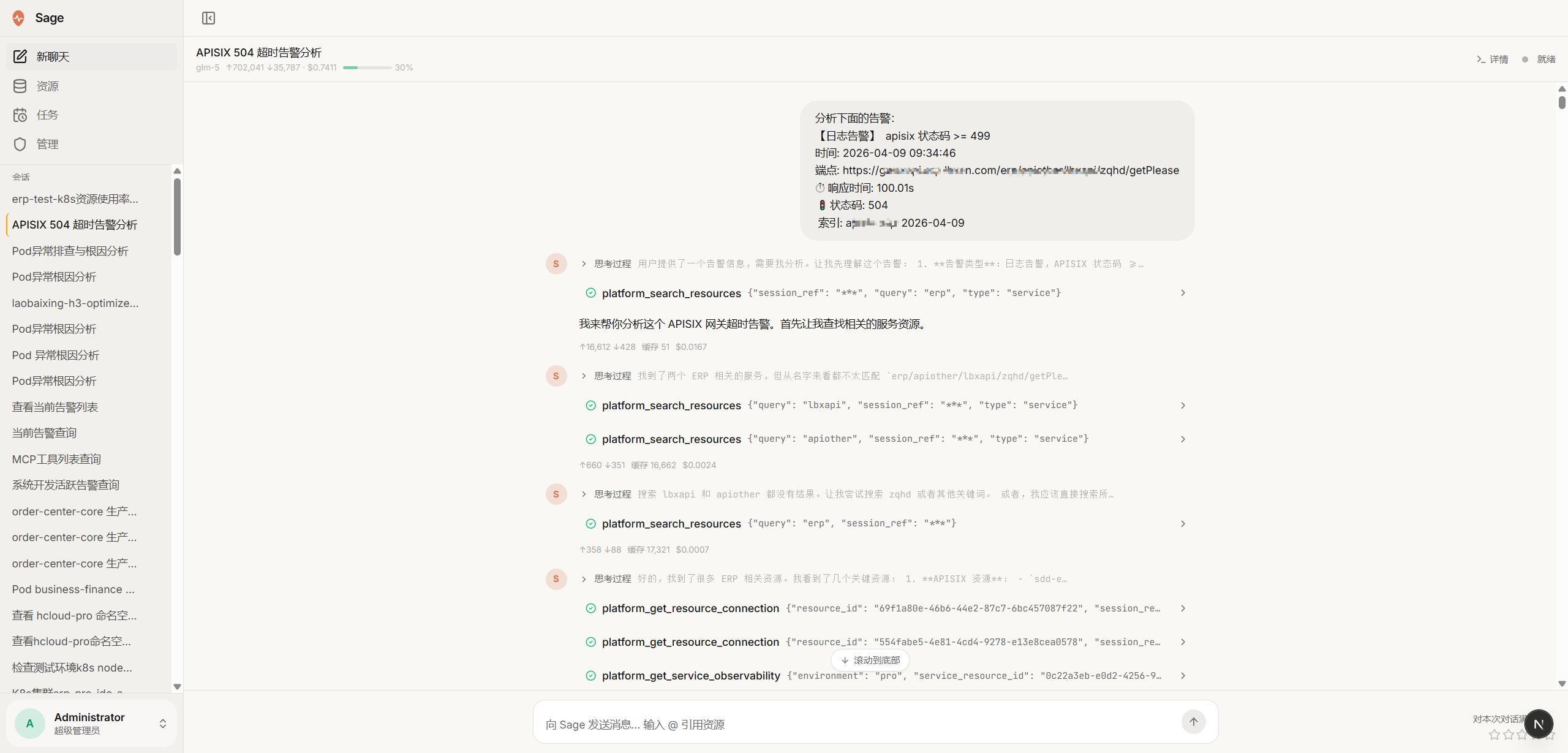
自然语言输入 → AI 多系统并行分析 → 根因报告 + 处置建议,全程工具调用可见
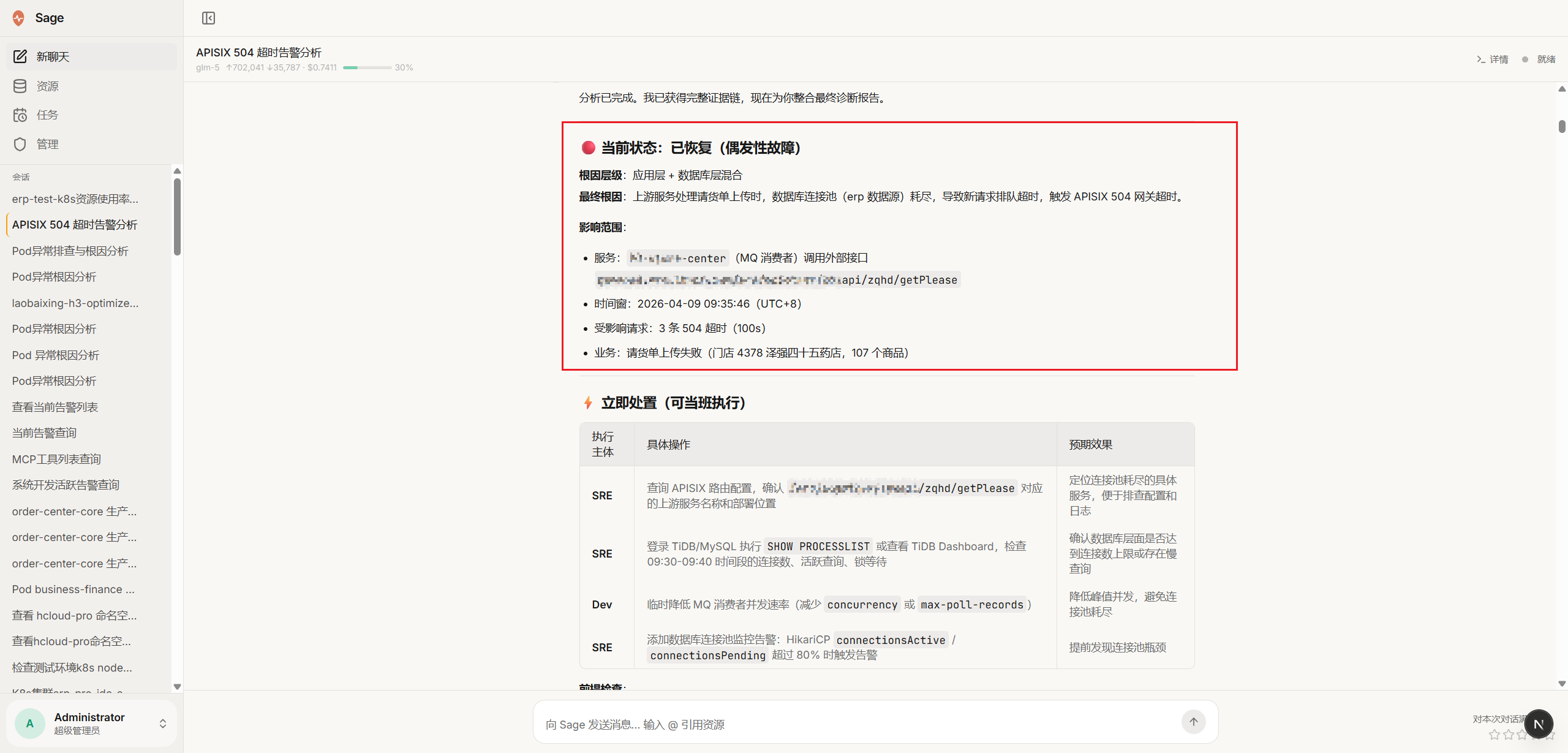
AI 的每一步推理和工具调用实时展示,子代理执行轨迹可展开回放,过程完全透明
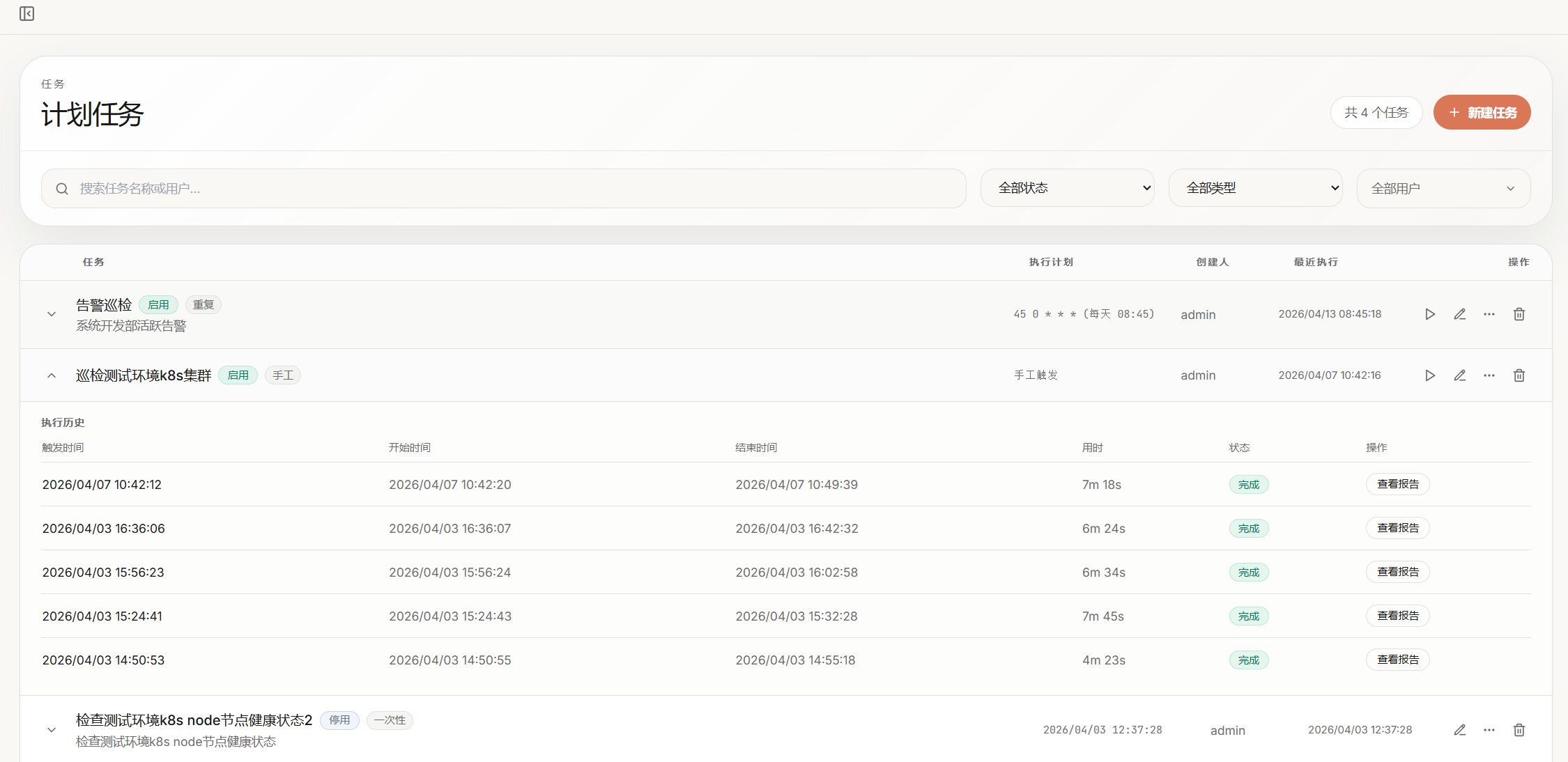
SOP 变成定时任务,结构化巡检报告自动生成,支持 Cron / 一次性 / 手工触发三种模式

巡检结论智能推送到企微群,区分执行异常与巡检告警,精准 @值班人员,避免告警疲劳
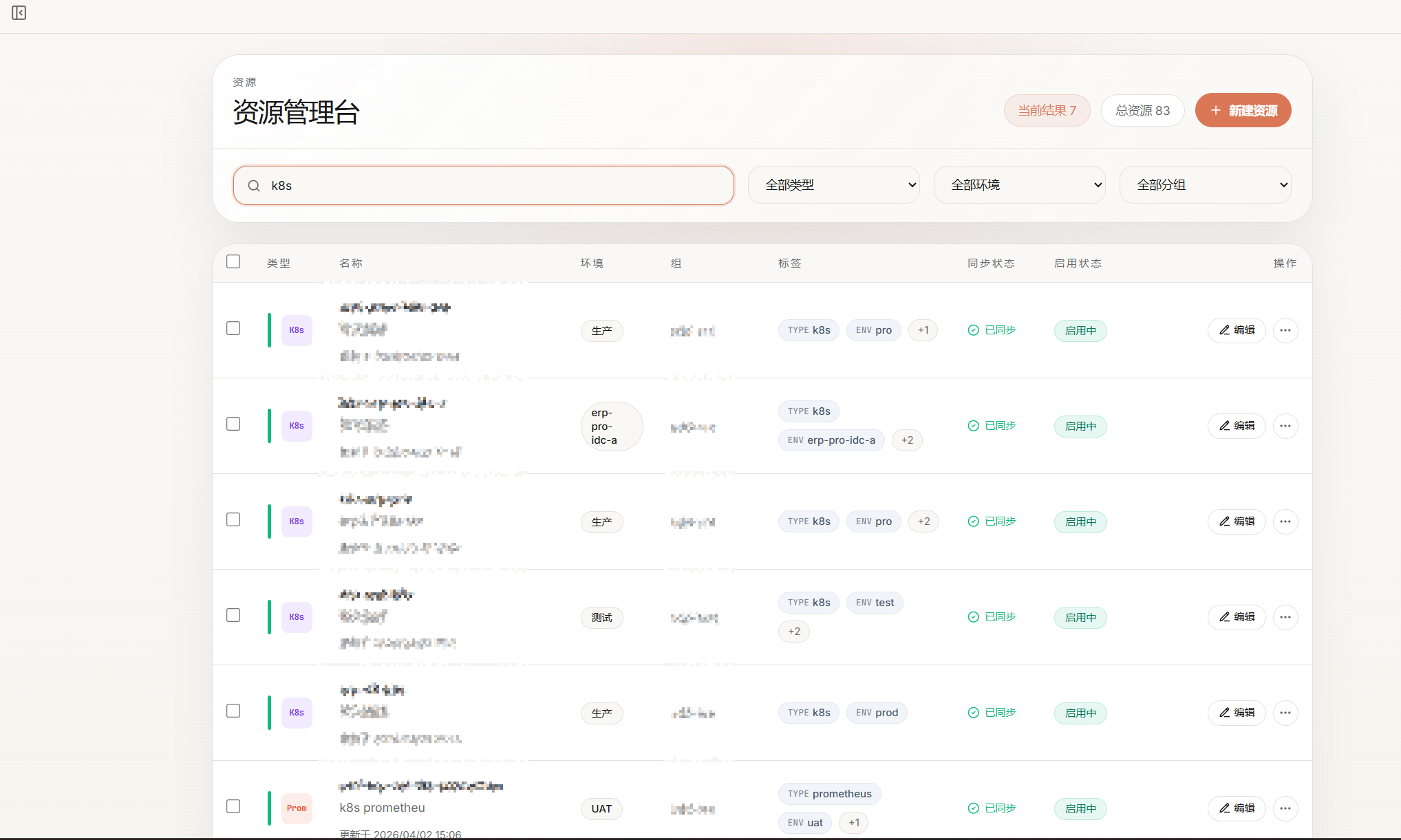
统一纳管多类型基础设施资源,三级权限模型,组内自助授权,凭据 AES-256-GCM 加密存储
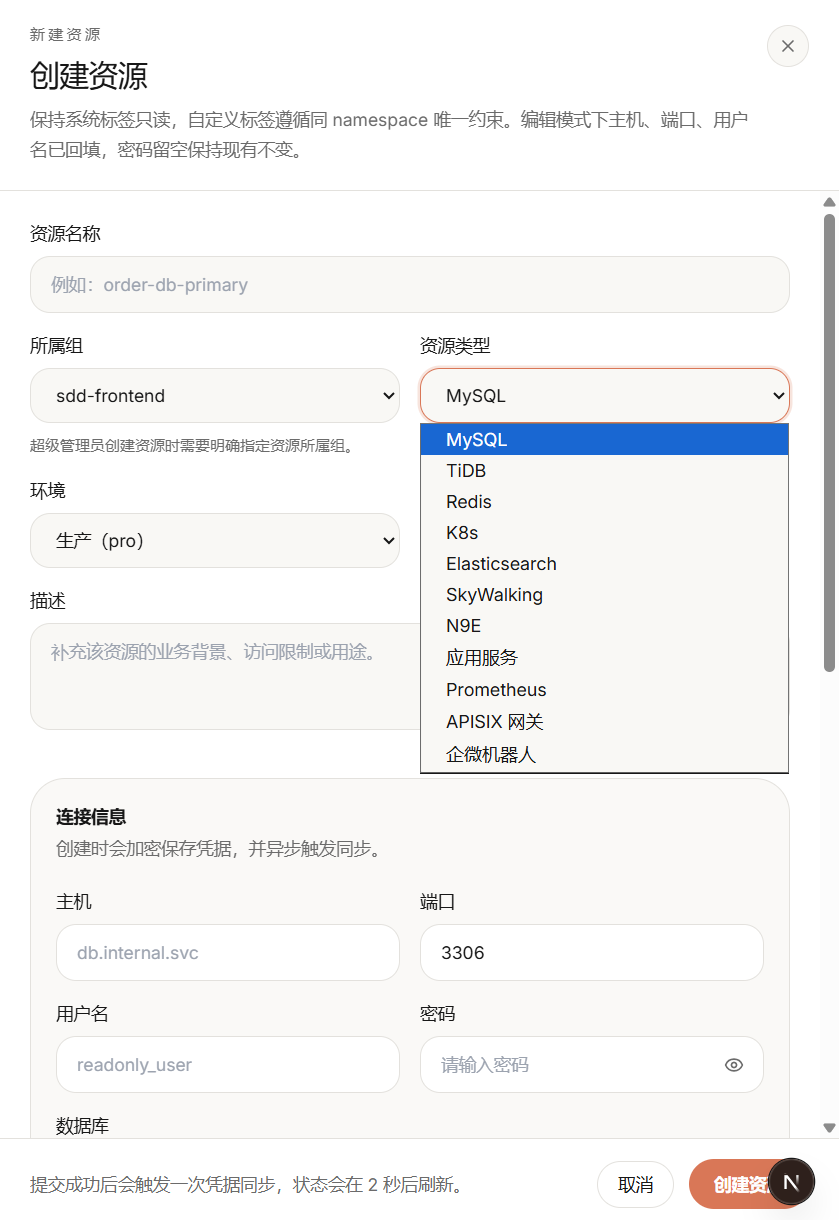
填写资源信息后自动加密存储凭据,支持 SSH 通道连接测试,配置完成即可验证连通性
